02-序列建模实战¶
学习时间: 约 6-8 小时 难度级别: ⭐⭐⭐⭐ 中高级 前置知识: 循环神经网络基础、 LSTM/GRU 、 PyTorch 学习目标: 掌握基于 RNN 的文本分类、情感分析、时间序列预测、 Seq2Seq 模型
目录¶
- 1. 文本分类实战
- 2. 情感分析
- 3. 时间序列预测
- 4. 序列到序列模型( Seq2Seq )
- 5. 注意力机制在序列中的应用
- 6. Teacher Forcing
- 7. Beam Search
- 8. 完整代码项目:机器翻译
- 9. 练习与自我检查
1. 文本分类实战¶

1.1 数据预处理流程¶
Python
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from collections import Counter
import re
class Vocabulary:
"""词汇表构建"""
def __init__(self, min_freq=2): # __init__构造方法,创建对象时自动调用
self.word2idx = {'<pad>': 0, '<unk>': 1, '<bos>': 2, '<eos>': 3}
self.idx2word = {v: k for k, v in self.word2idx.items()}
self.min_freq = min_freq
def build(self, texts):
counter = Counter() # Counter统计元素出现次数
for text in texts:
tokens = self.tokenize(text)
counter.update(tokens)
for word, freq in counter.most_common():
if freq >= self.min_freq:
idx = len(self.word2idx)
self.word2idx[word] = idx
self.idx2word[idx] = word
def tokenize(self, text):
text = text.lower().strip() # 链式调用,连续执行多个方法
text = re.sub(r'[^\w\s]', '', text)
return text.split()
def encode(self, text, max_len=None):
tokens = self.tokenize(text)
indices = [self.word2idx.get(t, 1) for t in tokens] # 列表推导式,简洁创建列表
if max_len:
indices = indices[:max_len]
indices += [0] * (max_len - len(indices))
return indices
def __len__(self): # __len__定义len()的行为
return len(self.word2idx)
class TextDataset(Dataset):
def __init__(self, texts, labels, vocab, max_len=200):
self.texts = texts
self.labels = labels
self.vocab = vocab
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx): # __getitem__定义索引访问行为
encoded = self.vocab.encode(self.texts[idx], self.max_len)
return torch.tensor(encoded), torch.tensor(self.labels[idx])
1.2 LSTM 文本分类模型¶
Python
class LSTMClassifier(nn.Module): # 继承nn.Module定义神经网络层
def __init__(self, vocab_size, embed_dim=128, hidden_dim=256,
num_classes=2, num_layers=2, dropout=0.5):
super().__init__() # super()调用父类方法
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.lstm = nn.LSTM(embed_dim, hidden_dim, num_layers,
batch_first=True, bidirectional=True, dropout=dropout)
self.attention = nn.Linear(hidden_dim * 2, 1)
self.classifier = nn.Sequential(
nn.Dropout(dropout),
nn.Linear(hidden_dim * 2, hidden_dim),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, num_classes)
)
def attention_pool(self, lstm_output, mask=None):
"""自注意力池化"""
scores = self.attention(lstm_output).squeeze(-1) # (batch, seq_len) # squeeze去除大小为1的维度
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
weights = torch.softmax(scores, dim=1).unsqueeze(2) # (batch, seq_len, 1) # unsqueeze增加一个维度
weighted = (lstm_output * weights).sum(dim=1) # (batch, hidden*2)
return weighted
def forward(self, x):
mask = (x != 0).float()
embedded = self.embedding(x)
output, _ = self.lstm(embedded)
pooled = self.attention_pool(output, mask)
return self.classifier(pooled)
2. 情感分析¶
Python
class SentimentAnalyzer(nn.Module):
"""情感分析模型(支持细粒度情感:1-5星)"""
def __init__(self, vocab_size, embed_dim=300, hidden_dim=256, num_classes=5):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.lstm = nn.LSTM(embed_dim, hidden_dim, num_layers=2,
batch_first=True, bidirectional=True, dropout=0.3)
self.fc = nn.Sequential(
nn.Linear(hidden_dim * 2, hidden_dim),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(hidden_dim, num_classes)
)
def forward(self, x):
embedded = self.embedding(x)
output, (h_n, _) = self.lstm(embedded)
hidden = torch.cat([h_n[-2], h_n[-1]], dim=1) # [-1]负索引取最后一个元素
return self.fc(hidden)
def train_sentiment(model, train_loader, val_loader, epochs=10, device='cuda'):
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=2)
for epoch in range(epochs):
model.train() # train()开启训练模式
total_loss, correct, total = 0, 0, 0
for texts, labels in train_loader:
texts, labels = texts.to(device), labels.to(device) # .to(device)将数据移至GPU/CPU
outputs = model(texts)
loss = criterion(outputs, labels)
optimizer.zero_grad() # 清零梯度,防止梯度累积
loss.backward() # 反向传播计算梯度
torch.nn.utils.clip_grad_norm_(model.parameters(), 5.0)
optimizer.step() # 根据梯度更新模型参数
total_loss += loss.item() * texts.size(0) # .item()将单元素张量转为Python数值
_, pred = outputs.max(1)
correct += pred.eq(labels).sum().item()
total += labels.size(0)
val_acc = evaluate_model(model, val_loader, device)
scheduler.step(total_loss / total)
print(f"Epoch {epoch+1}: Loss={total_loss/total:.4f}, "
f"Train Acc={100*correct/total:.2f}%, Val Acc={val_acc:.2f}%")
def evaluate_model(model, loader, device):
model.eval() # eval()开启评估模式(关闭Dropout等)
correct, total = 0, 0
with torch.no_grad(): # 禁用梯度计算,节省内存
for texts, labels in loader:
texts, labels = texts.to(device), labels.to(device)
_, pred = model(texts).max(1)
correct += pred.eq(labels).sum().item()
total += labels.size(0)
return 100 * correct / total
3. 时间序列预测¶

Python
import numpy as np
class TimeSeriesDataset(Dataset):
"""时间序列数据集"""
def __init__(self, data, window_size=30, forecast_horizon=1):
self.data = torch.FloatTensor(data)
self.window_size = window_size
self.forecast_horizon = forecast_horizon
def __len__(self):
return len(self.data) - self.window_size - self.forecast_horizon + 1
def __getitem__(self, idx):
x = self.data[idx:idx+self.window_size].unsqueeze(-1)
y = self.data[idx+self.window_size:idx+self.window_size+self.forecast_horizon]
return x, y
class LSTMForecaster(nn.Module):
"""LSTM时间序列预测"""
def __init__(self, input_dim=1, hidden_dim=64, num_layers=2, forecast_horizon=1):
super().__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True, dropout=0.2)
self.fc = nn.Sequential(
nn.Linear(hidden_dim, 32),
nn.ReLU(),
nn.Linear(32, forecast_horizon)
)
def forward(self, x):
output, (h_n, _) = self.lstm(x)
return self.fc(h_n[-1])
# 使用示例
# 生成正弦波数据
t = np.linspace(0, 100, 2000)
data = np.sin(t) + 0.1 * np.random.randn(len(t))
dataset = TimeSeriesDataset(data, window_size=50, forecast_horizon=10)
loader = DataLoader(dataset, batch_size=32, shuffle=True) # DataLoader批量加载数据,支持shuffle和多进程
model = LSTMForecaster(input_dim=1, hidden_dim=64, forecast_horizon=10)
4. 序列到序列模型( Seq2Seq )¶
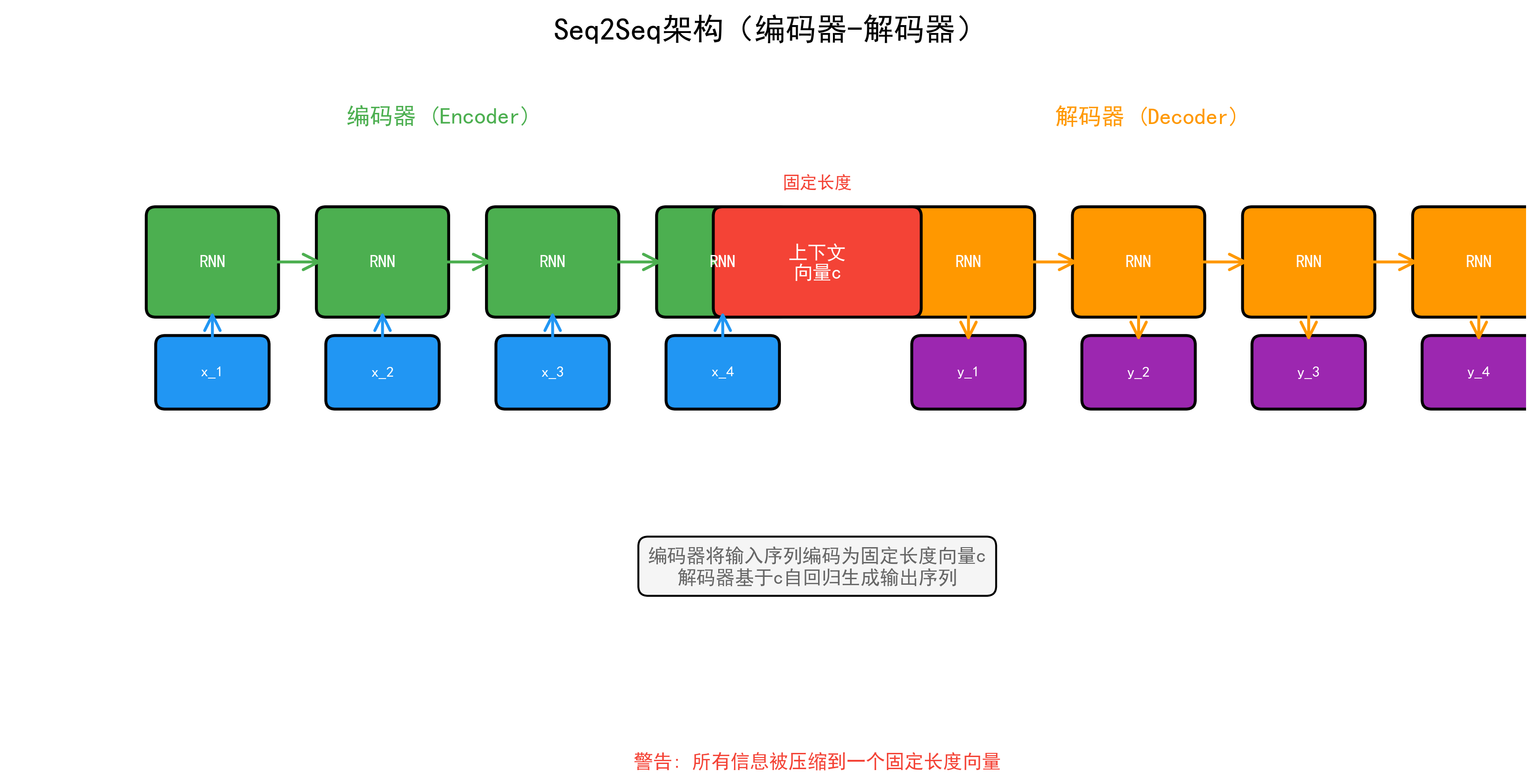
4.1 编码器-解码器架构¶
Python
class Encoder(nn.Module):
"""Seq2Seq 编码器"""
def __init__(self, vocab_size, embed_dim, hidden_dim, num_layers=2, dropout=0.5):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, num_layers,
batch_first=True, dropout=dropout, bidirectional=True)
self.fc_h = nn.Linear(hidden_dim * 2, hidden_dim)
self.fc_c = nn.Linear(hidden_dim * 2, hidden_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, (h_n, c_n) = self.lstm(embedded)
# 合并双向隐藏状态
h_n = torch.cat([h_n[0::2], h_n[1::2]], dim=2)
c_n = torch.cat([c_n[0::2], c_n[1::2]], dim=2)
h_n = torch.tanh(self.fc_h(h_n))
c_n = torch.tanh(self.fc_c(c_n))
return outputs, (h_n, c_n)
class Decoder(nn.Module):
"""Seq2Seq 解码器"""
def __init__(self, vocab_size, embed_dim, hidden_dim, num_layers=2, dropout=0.5):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, num_layers,
batch_first=True, dropout=dropout)
self.fc_out = nn.Linear(hidden_dim, vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, trg, hidden):
embedded = self.dropout(self.embedding(trg))
output, hidden = self.lstm(embedded, hidden)
prediction = self.fc_out(output)
return prediction, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
batch_size, trg_len = trg.shape
trg_vocab_size = self.decoder.fc_out.out_features
outputs = torch.zeros(batch_size, trg_len, trg_vocab_size, device=self.device)
enc_outputs, hidden = self.encoder(src)
input_token = trg[:, 0:1] # <bos> token
for t in range(1, trg_len):
output, hidden = self.decoder(input_token, hidden)
outputs[:, t:t+1] = output
# Teacher Forcing
if torch.rand(1).item() < teacher_forcing_ratio:
input_token = trg[:, t:t+1]
else:
input_token = output.argmax(dim=-1)
return outputs
5. 注意力机制在序列中的应用¶
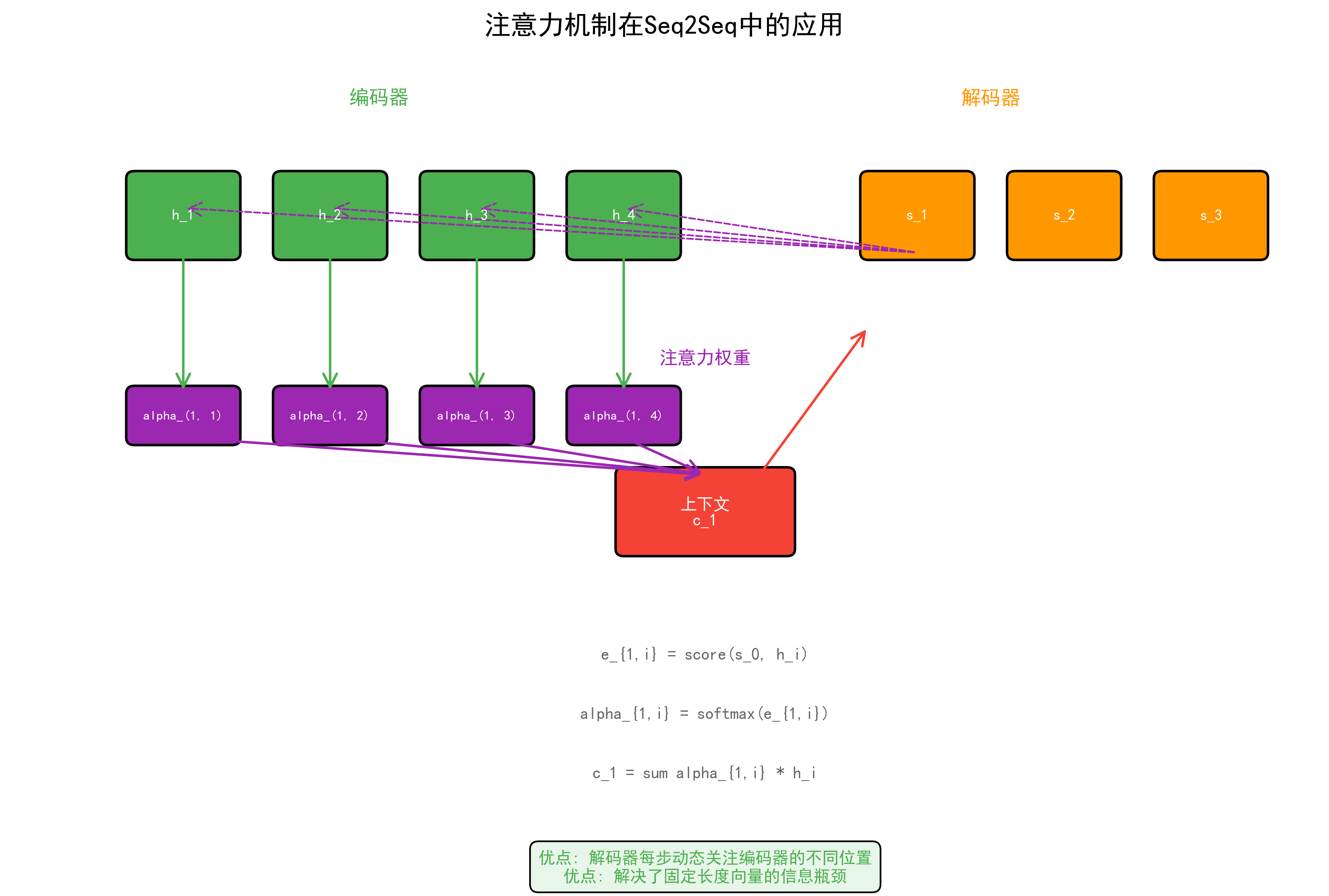
5.1 Bahdanau 注意力(加性注意力)¶
Python
class BahdanauAttention(nn.Module):
"""Bahdanau (Additive) 注意力"""
def __init__(self, hidden_dim, enc_dim):
super().__init__()
self.W_q = nn.Linear(hidden_dim, hidden_dim)
self.W_k = nn.Linear(enc_dim, hidden_dim)
self.v = nn.Linear(hidden_dim, 1)
def forward(self, query, keys, mask=None):
"""
query: (batch, 1, hidden_dim) — 解码器当前隐藏状态
keys: (batch, src_len, enc_dim) — 编码器所有输出
"""
scores = self.v(torch.tanh(self.W_q(query) + self.W_k(keys)))
scores = scores.squeeze(-1) # (batch, src_len)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
weights = torch.softmax(scores, dim=-1)
context = torch.bmm(weights.unsqueeze(1), keys)
return context, weights
class AttentionDecoder(nn.Module):
"""带注意力的解码器"""
def __init__(self, vocab_size, embed_dim, hidden_dim, enc_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.attention = BahdanauAttention(hidden_dim, enc_dim)
self.lstm = nn.LSTM(embed_dim + enc_dim, hidden_dim, batch_first=True)
self.fc_out = nn.Linear(hidden_dim + enc_dim + embed_dim, vocab_size)
def forward(self, trg_token, hidden, enc_outputs, mask=None):
embedded = self.embedding(trg_token)
query = hidden[0][-1:].permute(1, 0, 2)
context, attn_weights = self.attention(query, enc_outputs, mask)
lstm_input = torch.cat([embedded, context], dim=-1)
output, hidden = self.lstm(lstm_input, hidden)
prediction = self.fc_out(torch.cat([output, context, embedded], dim=-1))
return prediction, hidden, attn_weights
6. Teacher Forcing¶
Teacher Forcing 在训练时使用真实标签而非模型预测作为下一步输入。
Python
def train_with_scheduled_teacher_forcing(model, loader, optimizer, criterion,
epoch, total_epochs):
"""带调度的 Teacher Forcing"""
# 线性衰减 teacher forcing ratio
tf_ratio = max(0.0, 1.0 - epoch / total_epochs)
model.train()
total_loss = 0
for src, trg in loader:
optimizer.zero_grad()
output = model(src, trg, teacher_forcing_ratio=tf_ratio)
loss = criterion(output[:, 1:].reshape(-1, output.size(-1)), trg[:, 1:].reshape(-1)) # reshape重塑张量形状
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
total_loss += loss.item()
return total_loss / len(loader)
7. Beam Search¶

Python
def beam_search(model, src, beam_width=5, max_len=50, bos_idx=2, eos_idx=3):
"""Beam Search 解码"""
model.eval()
with torch.no_grad():
enc_outputs, hidden = model.encoder(src)
# 初始化 beam
beams = [(torch.tensor([[bos_idx]], device=src.device), hidden, 0.0)]
completed = []
for step in range(max_len):
candidates = []
for seq, hidden, score in beams:
if seq[0, -1].item() == eos_idx:
completed.append((seq, score))
continue
token = seq[:, -1:]
output, new_hidden = model.decoder(token, hidden)
log_probs = torch.log_softmax(output.squeeze(1), dim=-1)
topk_probs, topk_ids = log_probs.topk(beam_width)
for i in range(beam_width):
new_seq = torch.cat([seq, topk_ids[:, i:i+1]], dim=1)
new_score = score + topk_probs[0, i].item()
candidates.append((new_seq, new_hidden, new_score))
if not candidates:
break
# 选择得分最高的 beam_width 个
candidates.sort(key=lambda x: x[2] / x[0].size(1), reverse=True) # 长度归一化
beams = candidates[:beam_width]
# 返回最佳序列
completed.extend([(seq, score) for seq, _, score in beams])
completed.sort(key=lambda x: x[1] / x[0].size(1), reverse=True)
return completed[0][0] if completed else beams[0][0]
8. 完整代码项目:机器翻译¶
Python
"""
完整的 Seq2Seq + Attention 机器翻译项目框架
"""
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
def build_translation_model(src_vocab_size, trg_vocab_size, device):
"""构建翻译模型"""
embed_dim = 256
hidden_dim = 512
enc_dim = hidden_dim * 2 # 双向
encoder = Encoder(src_vocab_size, embed_dim, hidden_dim)
decoder = AttentionDecoder(trg_vocab_size, embed_dim, hidden_dim, enc_dim)
model = nn.Module()
model.encoder = encoder
model.decoder = decoder
model = model.to(device)
return model
def translate(model, sentence, src_vocab, trg_vocab, device, max_len=50):
"""翻译单个句子"""
model.eval()
tokens = src_vocab.encode(sentence)
src = torch.tensor([tokens], device=device)
with torch.no_grad():
enc_outputs, hidden = model.encoder(src)
input_token = torch.tensor([[2]], device=device) # <bos>
result = []
for _ in range(max_len):
output, hidden, attn = model.decoder(input_token, hidden, enc_outputs)
next_token = output.argmax(dim=-1)
if next_token.item() == 3: # <eos>
break
result.append(trg_vocab.idx2word.get(next_token.item(), '<unk>'))
input_token = next_token
return ' '.join(result)
# 训练循环
def train_translation(model, train_loader, val_loader, epochs=30, device='cuda'):
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss(ignore_index=0)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=3, factor=0.5)
for epoch in range(epochs):
model.train()
epoch_loss = 0
for src, trg in train_loader:
src, trg = src.to(device), trg.to(device)
tf_ratio = max(0.0, 1.0 - epoch / epochs)
optimizer.zero_grad()
# 完整的前向传播和损失计算
enc_outputs, hidden = model.encoder(src)
input_token = trg[:, 0:1]
loss = 0
for t in range(1, trg.size(1)):
output, hidden, _ = model.decoder(input_token, hidden, enc_outputs)
loss += criterion(output.squeeze(1), trg[:, t])
if torch.rand(1).item() < tf_ratio:
input_token = trg[:, t:t+1]
else:
input_token = output.argmax(dim=-1)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_loader)
scheduler.step(avg_loss)
print(f"Epoch {epoch+1}: Loss = {avg_loss:.4f}")
9. 练习与自我检查¶
练习题¶
- 文本分类:使用 LSTM 在 IMDB 数据集上实现情感分类,达到 85%+ 准确率。
- 时间序列:用 LSTM 预测股票价格或气温序列,可视化预测结果。
- Seq2Seq:实现一个简单的英文到法文翻译系统。
- 注意力可视化:在翻译模型中可视化注意力权重热力图。
- Beam Search:实现 Beam Search 并对比贪心解码和 Beam Search 的翻译质量。
自我检查清单¶
- 能实现完整的文本预处理流水线(分词→词表→编码→填充)
- 理解并能实现 LSTM 文本分类器
- 能用 LSTM 做时间序列预测
- 理解 Seq2Seq 编码器-解码器架构
- 理解 Bahdanau 注意力的计算过程
- 能实现 Teacher Forcing 和调度策略
- 理解 Beam Search 的原理和实现